





Cut CI/CD Costs by 27% & 2x Deployment Speed with GitHub Actions on EKS Auto

On April 5, 2025 I did a live stream on how to run Github Actions Self Hosted Runners on EKS Auto with AWS Heroes Arshad Zackeriya and Jones Zachariah Noel.
Disclaimer:
No Beagles were harmed. Slightly annoyed, maybe — but unharmed.
The results
{Performance, Speed, Cost}were not only astonishing but impeccable and promising enough to adopt this solution at the enterprise level. This solution isn’t just AWS agnostic, with the knowledge gained in this blog can be extended to Azure, google or if you are running K8 own your own bare metal servers.For the people who wants to jump straight in to trying the solution can follow my repo here
This is going to be a bit of a long one, so grab a coffee, get comfy, and make sure you’re sitting in your optimal developer position™ — you know the one.
Why this solution
I work as a senior DevOps Engineer at Colorkrew where we have a lot of products and to support the development workflow we have lot of GitHub repositories.
As we started to increase our product portfolio, our CI/CD pipelines also started to become more complex, concurrent and frequent leading to the need of more computation power and eventually more robust infrastructure layer which supports our growing needs.
Running Github Actions on default free machines (called as runners) started to become slow and the initial solution was to either use Large hosted runners by GitHub which are paid or run the runners on our Infrastructure like Kubernetes.
So I started to compare both solutions on performance, speed and cost and this lead to the inception of this running GitHub’s self hosted runners on EKS Auto.
Self Hosted Runner Concept on K8
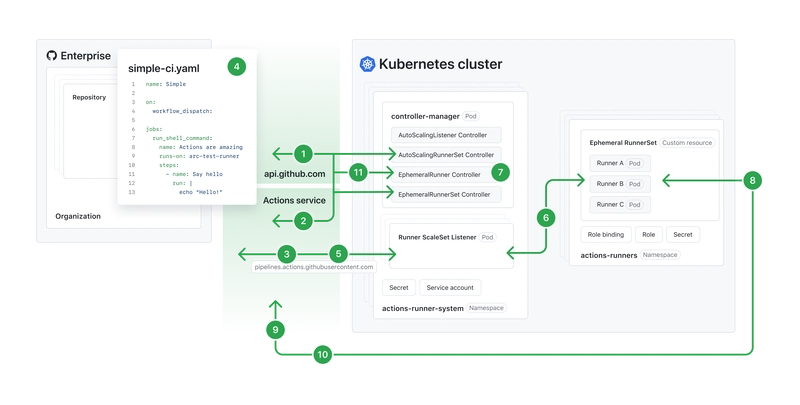
Runners: The machines (servers or virtual environments) that actually execute the jobs defined in your workflows. When you manage called as Self Hosted runners otherwise GitHub Hosted runners. Runners are ephemeral in nature.
Runner Scale Sets: Think of it as a logical grouping of runners that are homogeneous in nature which means all runners under a particular group will have same configuration. Can be installed at repository, organization or enterprise level.
If you want heterogeneous setup which means different configuration for runners for different ci/cd jobs then you need a multiple runner scale sets.
Another important thing to know about Runner scale sets are that you configure how many minimum and maximum runners you want all the time.
Name of Runner Scale Sets: Runner scale sets are addressable by their name so remember it because when you need to specify that name of runner scale set in the runs on: property of GHA to assign that workflow on on a particular runner scale set.
-
Endpoints: ARC talks to two endpoints
api.github.comandpipelines.actions.githubusercontent.com. Make sure your organization’s firewall, proxies, nat gateway whatever being used to access internet should be configured to allow the above endpoints for ARC controller. -
ARC controller: contains of 2 elements/pods.
-
controller-manager: First pod that comes online. This has different controllers managing different resources in the cluster. Important one to understand isAutoScalingListenerController manages the listener pod.- Responsible for creating the resources and making sure that match the desired count and state.
-
Runner ScaleSet Listener: Manages the decision making about scaling needs. Responsible to decide how many runners to create. Each listener has its own pod which means 1 listener pod per runner scale set. If you have 2 runner scale set then 2 listener pods either on same namespace like controller manager or different namespace ( configurable)
-
I thought should give easier explanation in my own analogies


Actions Runner Controller (ARC is like the manager of a smart, automated coffee shop — it watches how many customers are coming in (workflows) and instantly hires or releases baristas (runners) as needed.
Instead of having baristas standing around all day just in case, ARC spins up temporary baristas (containers in Kubernetes) only when customers arrive, and lets them go when the work is done. This keeps the system fast, efficient, and cost-effective.
With Runner Scale Sets, you can define the rules for how many baristas you want at any given time, based on how busy your shop is — and ARC handles the rest.
You can read more about detailed end to end workflow over here
Terraform Code Walkthrough
This repository provides infrastructure as code (IaC) to deploy auto-scaling GitHub Actions self-hosted runners on Amazon EKS using GitHub’s Actions Runner Controller (ARC).
Overview
This solution allows you to:
- Deploy a fully managed EKS cluster with auto-scaling capabilities
- Set up GitHub Actions Runner Controller (ARC) for managing self-hosted runners
- Configure auto-scaling runner sets that scale based on workflow demand
- Support Docker-in-Docker (DinD) runners for container-based workflows
Architecture

The infrastructure consists of:
- Amazon EKS cluster running in a custom VPC
- GitHub Actions Runner Controller deployed via Helm
- Auto-scaling runner sets configured to scale from 0 to meet demand
- Optional Docker-in-Docker (DinD) runner support
- Karpenter for node auto-scaling (configured but optional)
Prerequisites
- AWS CLI configured with appropriate permissions
- Terraform v1.0.0+
- kubectl
- Helm v3+
- A GitHub repository or organization where you want to deploy runners
- GitHub App credentials for the Actions Runner Controller
Setup Instructions
1. Configure AWS
…
Setting Up Auto-Scaling GitHub Actions Self-Hosted Runners on Amazon EKS
Introduction
In this walkthrough, we’ll set up GitHub Actions Runner Controller (ARC) on Amazon EKS to automatically scale self-hosted runners based on workflow demand.
Project Structure
Here’s the structure of our implementation:
eks-auto-self-hosted-runners/
├── README.md
├── architecture/
├── commit_log.txt
├── scripts/
└── terraform/
├── base/
└── modules/
├── arc/
├── eks/
├── karpenter_config/
└── vpc/
1. Root directory - Contains the main README and architecture diagrams
2. scripts/ - Contains utility scripts for cleanup and performance testing
3. terraform/ - The main infrastructure code
base/ - The entry point for Terraform deployment
modules/ - Reusable Terraform modules:
arc/ - Actions Runner Controller configuration
eks/ - EKS cluster configuration
karpenter_config/ - Node auto-scaling configuration
vpc/ - Network infrastructure configuration
Architecture Overview

Our solution uses the following components:
- Amazon EKS Auto: Managed Kubernetes service to host our runner infrastructure with Karpenter for provisioning nodes on-demand for runners compute
- GitHub Actions Runner Controller (ARC): Kubernetes controller that manages self-hosted runners
- Terraform: Infrastructure as Code tool to deploy and manage all components
The architecture allows GitHub Actions workflows to dynamically request runners, which are provisioned on-demand in our EKS cluster and automatically scaled down when not needed.
Step 1: Setting Up the Infrastructure
VPC Configuration
We start by creating a VPC with public and private subnets. Our VPC configuration uses a CIDR block of 10.0.0.0/16 with subnets spread across two availability zones. The
private subnets host our EKS nodes, while public subnets are used for NAT gateways and load balancers.
The configuration in terraform/base/vpc.tf references the VPC module and sets up all necessary networking components with appropriate tagging for Kubernetes integration.
EKS Cluster Setup
Next, we create an EKS cluster using the EKS module defined in terraform/modules/eks. Our cluster runs Kubernetes version 1.31 and includes a system node group for running
essential cluster services.
The terraform/base/eks.tf file configures the cluster with public endpoint access and places the worker nodes in the private subnets for enhanced security.
Step 2: Configuring EKS Auto’s pre-installed Karpenter for Auto-Scaling
EKS Auto comes with Karpenter pre-installed. We leverage Karpenter to provision and auto scale Ec2 spot instances from our desired Ec2 type, capacity and configuration for our GHA runner’s compute.
Our Karpenter configuration in terraform/base/karpenter_config.tf uses m7a instance types with spot pricing for cost efficiency. The consolidation policy is set to “WhenEmpty” with a 5-minute timeout, which means nodes will be removed when they’re no longer needed.
Key configuration parameters include:
• Instance types: m7a family with 8 CPUs
• Capacity type: Spot instances for cost savings
• Storage: 300GB with 5000 IOPS
• Availability zones: us-east-1a and us-east-1b
Step 3: Deploying Actions Runner Controller (ARC)
Now we deploy the GitHub Actions Runner Controller using the ARC module defined in terraform/modules/arc. The module is referenced in terraform/base/arc.tf with configuration parameters from locals.tf.
The ARC deployment consists of two main components:
- Controller: Manages the lifecycle of runner pods
- Runner Sets: Define the configuration for the runners
Controller Deployment
The controller is deployed using a Helm chart from the official GitHub Actions Runner Controller repository. The configuration is defined in terraform/modules/arc/controller.tf and uses values from helm/controller_values.yaml.
Runner Sets Configuration
We deploy two types of runner sets:
- Standard Runners: For general workflow jobs
- Docker-in-Docker (DinD) Runners: For jobs that need to build Docker images
- There is also another type of runner set called
Kubernetes modewhich should be used when organizations cannot afford to run docker with superuser context as in case DinD runners then use Kubernetes mode ( not covered in this blog)
- There is also another type of runner set called
The runner sets are defined in terraform/modules/arc/runner_sets.tf and use values from helm/arc_listener_values.yaml and helm/arc_listener_values_dind.yaml respectively.
Note: This is very important that Controller pod and runner scale set pod should be configured to be deployed on on-demand ec2 instance for reliability and ephermal runner pods should be configured to run spot instances.
# controller config for on demand node
nodeSelector:
karpenter.sh/nodepool: system
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
# listener config for on demand node
listenerTemplate:
spec:
nodeSelector:
karpenter.sh/nodepool: system
tolerations:
- key: "CriticalAddonsOnly"
operator: "Exists"
Step 4: GitHub Authentication Setup
ARC authenticates with GitHub using a GitHub App. The credentials are stored in Kubernetes secrets and used by the runner controller to authenticate with GitHub.
To set up authentication:
- Create a GitHub App with the necessary permissions
- Generate a private key for the app
- Store the app ID, installation ID, and private key in the terraform/modules/arc/secrets (Don’t forget to create it, gitignored) the directory
- The terraform/modules/arc/secrets.tf file creates a Kubernetes secret with these credentials
Step 5: Namespace Management
We create dedicated namespaces for ARC components:
- arc-systems: For the controller components
- arc-runners: For the runner pods
These namespaces are defined in terraform/modules/arc/namespaces.tf.
Step 6: Cleanup Handling
To ensure proper cleanup of resources, we’ve included a cleanup script in scripts/cleanup-finalizers.sh that removes finalizers from Kubernetes resources. This script is called during the Terraform destroy process to ensure resources are properly cleaned up.
The script handles various resource types including:
• AutoscalingRunnerSet
• EphemeralRunnerSet
• AutoscalingListener
• ServiceAccounts
• RoleBindings
• Roles
How It Works
- When a GitHub Actions workflow runs, it requests a runner with specific labels
- The ARC controller detects this request and creates a runner pod in the EKS cluster
- If needed, Karpenter provisions a new EC2 instance to host the runner pod
- The runner registers with GitHub and runs the workflow job
- After the job completes, the runner pod is terminated
- When no more runners are needed, Karpenter consolidates and removes unused nodes
Benefits of This Approach
- Cost Efficiency: Runners are only provisioned when needed and automatically scaled down when idle
- Flexibility: Custom runner environments can be defined to meet specific workflow requirements
- Scalability: The system can handle large numbers of concurrent workflows
- Security: Runners run in isolated Kubernetes pods with defined security contexts
- Reliability: Failed runners are automatically replaced, ensuring workflow reliability
How to test this solution
I have created 3 GHA of different types to test different scenarios.
Simple test
The first type is the simple GHA but important point to pay attention is runs-on parameter which uses arc-runner-set label.
The moment you run the first workflow it takes around 1 minute because Karpenter is provisioning an Ec2 instance.
Once it is provisioned and if you run the workflow again because Ec2 instance is already present the action completes its execution immediately.
Karpenter will delete the node if it’s unused for at least 5 minutes.
Now if you have latency sensitive requirement of running your actions immediately then set minRunners>0 for the runner scale set configuration
Concurrent job test
In this GHA I am running 5 concurrent jobs running for exactly 1 minute each triggered either through push or manually.
DinD job test
There are times when we want to run microservice in container like redis and do e2e testing.
That’s where we need Docker Inside Docker kind of GHA.
Important point to pay attention here is runs-on parameter which uses different runner set configured especially for dind workflows
In this workflow busy box container runs the main job which can talk to redis service container.
Github Large Hosted Runner vs Running Runners on EKS Auto
Performance & Speed
I tried to do the performance and speed comparison of 8 Core CPU vs our solution.
I tried to run the sleep-matrix GHA using auto-commit script for 10 minutes and every commit happening in every 45 seconds effectively simulating a concurrent job situations for both EKS Auto solution and Github large Runners and results were hands down in favor of our solution
Our solutions has stable performance with constant 1 minute 8 seconds Execution time throughout.


Price
This is little tricky and may not be 100% accurate comparison but still can be considered 70-80% accurate.
Assume over a 30‑day month with 1 hour of concurrent CI workloads per day (12 jobs running in parallel). Lets calculate the cost on our solution and as well on Github’s self hosted runners
For our solution

For Github’s large runner

There is also a cost Github Teams/ENterprise subscription. I am assuming it’s on cheaper side i.e Team’s plan for a team of 10 developers.

self‑hosting on EKS with m7a.2xlarge Spot nodes costs approximately $530.93, while GitHub’s 8‑core large hosted runners cost $731.20, yielding a savings of 27%.
Lets assume its not 1 hour now its 2 hour of concurrent CI workloads per day (12 jobs running in parallel)


yielding a savings of 58.6%
From a solutions architect perspective
By combining Amazon EKS Auto and GitHub Actions Runner Controller, we’ve created a solution that aligns with the AWS Well-Architected Framework:
Operational Excellence:
• Infrastructure as code through Terraform ensures consistent deployments
• Auto-scaling runners eliminate manual capacity management
• Clean separation of components improves maintainability
Security:
• GitHub App authentication with scoped access
• EKS security groups and IAM roles enforce least-privilege
• Private subnets reduce attack surface
Reliability:
• Multi-AZ deployment ensures high availability
• Auto-scaling from zero accommodates varying workloads without manual intervention
• EKS Auto’s Karpenter provides intelligent node provisioning, ensuring resources are available when needed
Performance Efficiency:
• On-demand scaling ensures resources are used only when needed
• Spot instances reduce costs while maintaining performance
• Customizable instance types allow optimization for specific workload requirements
• Docker-in-Docker support enables container-based workflows with minimal overhead
Cost Optimization:
• Scale-to-zero capability eliminates costs when no workflows are running
• Spot instances provide significant cost savings (up to 90%) compared to on-demand instances
• Resource consolidation through Karpenter’s WhenEmpty policy reduces idle resources
Sustainability:
• Efficient resource utilization through auto-scaling minimizes environmental impact
• Scale-to-zero capability reduces energy consumption during idle periods
• Reduced idle resources lower energy consumption
This solution provides organizations with a scalable, cost-effective platform for running GitHub Actions workflows while maintaining full control over their infrastructure. The architecture can easily scale from small development teams to enterprise-level deployments, adapting to changing workflow requirements without compromising on security or performance.
By leveraging AWS managed services like EKS and implementing infrastructure as code through Terraform, this solution reduces operational overhead while providing the flexibility needed
for modern CI/CD pipelines. The result is a robust, efficient platform that enables teams to focus on delivering value rather than managing infrastructure.
Follow The Zacs’ Show Talking AWS on YouTube or reach out to them if you want to share your knowledge on AWS.
Have some questions on this solution reach out to me over Linkedin, X.


 and Application Security Groups (ASGs)")
