




How Healthcare Procurement Data is Being Used to Evaluate Supplier Reliability

Table of Links
-
Domain and Task
-
Related Work
3.1. Text mining and NLP research overview
3.2. Text mining and NLP in industry use
-
4.6. XML parsing, data joining, and risk indices development
-
Experiment and Demonstration
-
Discussion
6.1. The ‘industry’ focus of the project
6.2. Data heterogeneity, multilingual and multi-task nature
2. Domain and Task
This work focuses on healthcare procurement, which has been rarely studied in the literature. The primary goal of the project is to develop a platform that allows the dynamic creation of a ‘supplier risk profile’ for each healthcare supplier. We envisage such a profile to consist of different ‘indices’ that evaluate different perspectives (e.g, capacity for supplying certain products, geographical coverage) of ‘risks’ for potential buyers to sign contracts with the supplier. This would enable questions such as ‘who are the suppliers able to supply this kind of medication’, ‘to what extent are they capable of supplying for this country’, or ‘are they able to supply such quantity’ to be easily answered. Such questions are often crucial for buyer decision making. However, the current procurement process relies on manually sifting through multiple lengthy documents to seek answers. This is a very resource consuming process. Understandably, an enabler of our primary goal would be a structured database of healthcare suppliers’ historical contract data. Thus the secondary goal of the project is to develop such a database and populate it with historical healthcare procurement data. While public procurement data is vastly available, as we shall explain in the following, there is a mixture of structured, semi-structured, and unstructured multilingual data that need to be mined and linked. Therefore, a major part of the project’s work is developing text mining and NLP solutions that automatically process large quantities of unstructured procurement data to mine information that can be used to populate the database. The goal of this article is therefore, to report the development of these text mining and NLP methods.
2.1. Data sources and complexity
The project targets procurement data from the ‘Tenders Electronic Daily’ (TED) platform, which is used by the EU governments to publish their public procurement related projects. TED publishes over 460,000 calls for tenders and contract awards in 26 official European languages per year, for about 420 billion euro of value. Each tender may be divided into multiple ‘lots’, where a lot is the smallest contract unit. Each lot may contain multiple items that are required. As an example, tender notice ‘2019/S 180-437985’[1] lists 47 lots from an NHS (UK) tender, with their sizes ranging from 2 to over 30 items. If a tender secures successful bids, a ‘contract award’ (or multiple awards) will be made and recorded in TED for the tender. In the following, for the sake of explainability, we assume there is one award for each tender (however in practice, our methods are applied to all awards that are available for a tender). Note the lots offered in a tender and the contract awards form a ‘many-to-many’ relationship. Namely, multiple lots can be awarded to a single entity and documented in one contract award; a single lot can also be awarded to multiple entities, forming multiple contract awards; further a single contract award can include one or multiple lots.
On TED, each tender and its corresponding contract award(s) has a structured XML file documenting key elements of information. We refer to these as ‘tender XML’ and ‘award XML’. An example of a tender XML is shown in Figure 1. Award XMLs generally follow the same structure. Tender XMLs document information such as the buyer, the lots, items of lots, contract criteria, etc. Award XMLs document the buyer, the lots, the awarded suppliers for each lot, contract value, quantity, etc. Each tender may also have a collection of ‘attachment documents’ that provide further details of the tender, especially on lots and items (‘tender attachments’)



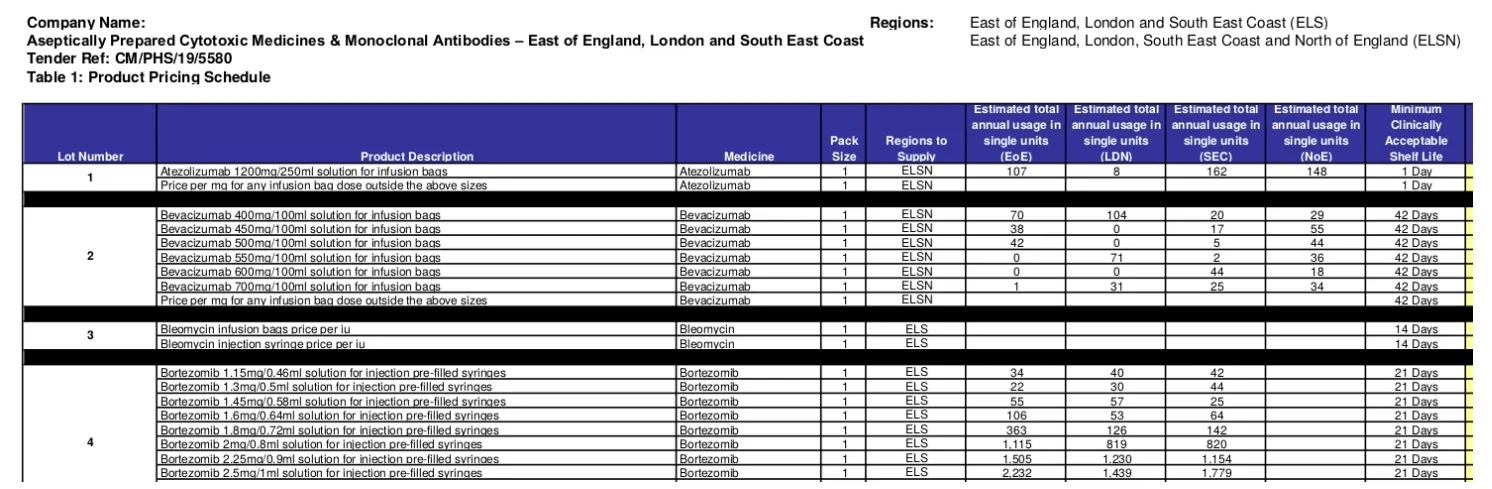
Given the availability of tender and award XMLs, one may consider the task of developing and populating the database to be easy. However, the data in reality is far more complicated. First and foremost, the tender and award XMLs are often incomplete. The predominant missing information is lot and item information. As an example, the tender XML for ‘2019/S 180-437985’, mentions 47 lots in the tender, without detailing the specific items but a lot reference number. This critical information is available from a bulk download of 7 tender attachments (PDFs). Both the tender and award XMLs then cross-reference these data sources through the use of the lot references. Recovering such information is crucial to building the supplier risk profile, which needs to account for the range and quantity of products that a supplier has supplied in the past. Second, not every tender attachment is relevant for our aim. Among those for ‘2019/S 180-437985’, two PDFs list the actual lots and items (e.g., Figure 2), while others document specifications, requirements, regulations and protocols etc. Third, not every page of a relevant attachment contains relevant information. For example, Figure 3 shows that in another tender, lots and items are described in one page but different sections of a long document. Fourth, as it is already shown in Figures 2 and 3, there is a significant discrepancy in how lot and item information is described within the same country, or indeed, even the same organisation. This discrepancy has been observed at different levels such as: the use of structured formatting (e.g., free text v.s. tables/lists); the amount of information encoded (e.g., the table in Figure 2 lists 16 columns (attributes) for each item) even for the same kinds of products/services; and the semantics of structure where structures are adopted (e.g., the order and names of columns). Such a high level of complexity and inconsistency could be one major reason why there has been a lack of text mining and NLP studies or applications for healthcare procurement.



Authors:
(1) Ziqi Zhang*, Information School, the University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., London ([email protected]);
(3) Richard Freeman, Vamstar Ltd., London ([email protected]);
(4) Rowida Alfrjani, Information School, the University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, Information School, the University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]).
[1] https://ted.europa.eu/udl?uri=TED:NOTICE:437985-2019:TEXT:EN:HTML, last accessed: Nov 2022



