




")
How 'Simple' Are AI Wrappers, Really?

Many developers need to build apps with LLMs but find that creating a simple abstraction on top of something like Gemini/ChatGPT/etc is challenging. Additionally, there aren’t many established resources on this topic, like there are with system design, leaving new developers unsure of where to begin.
\
Usually the simplest possible “simple wrapper” architecture looks like this (source):
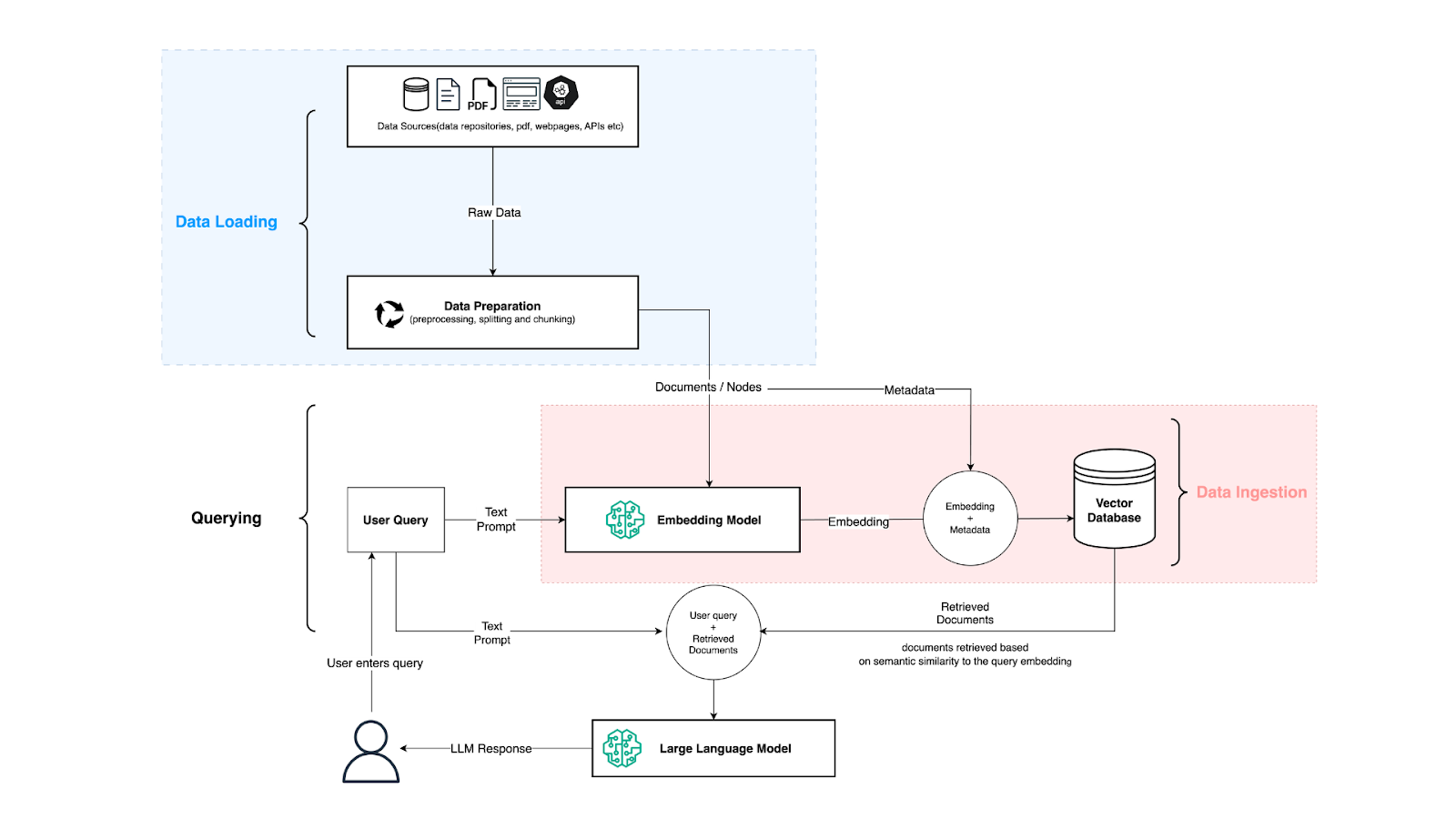
\
This article offers fundamental definitions that have proven useful in my own “simple wrappers” development. I’ll illustrate these definitions with practical examples (mostly built on top of GeminiAgentsToolkit), enabling you to easily replicate them when needed. The goal is to equip you with a basic understanding of these concepts, making your first “simple LLM wrapper” more scalable and supportable. Do not expect all the answers – this is a topic worthy of a book – it’s designed to be a clear starting point. These definitions will serve as a foundation for exploring more specific problems and their solutions in future discussions.
Definition – Tools
A Tool is a self-contained piece of code designed to perform a specific action and meet two key requirements for effective use by an LLM:
\
- LLM-Understandable Documentation: The Tool must have clear and comprehensive documentation that enables the target LLM to understand how to use it. Think of it as documentation designed for another developer – clear, concise, and complete. Essentially, almost any function you’ve written could qualify as a Tool (if you had documented it well enough).
- LLM-Compatible Inputs: The Tool should only accept input parameters of data types supported by the LLM you’re using. While specifics vary across LLMs and their tool-calling implementations, this typically means accepting only numbers or strings.
\
Tools are more or less part of the Agents that is a classical software. Here is an example of the Tool that provides functionality to execute query against BigQuery table – BigQueryHelper. This class really should have been named – BigQueryTool, but naming, as we all know, is the most complex thing in computer science (CS). Also, keep in mind that I am pointing to the specific class/file that only includes a tool. The full repository itself contains a full agent and it just happened that it also includes tools in it. But tools and agents do not need to be coupled.
\
Tools can be easily independently tested (since, well, they are just classical code). It is even possible to test intellectual requirements to LLM in order for the LLM to be able to understand the prompt/documentation of the tool. Tools can be distributed separately from the agent. In fact I am a long believer that we will see, at some point, many Agent’s tools marketplaces/hubs that provide you with small tools that have very well defined docs/prompts and are well tested with different main LLMs. In facts one of my favorite Agents framework from HuggingFace going in exactly this direction, from their announcement article:
\
 Hub integrations: you can share and load tools to/from the Hub, and more is to come!
Hub integrations: you can share and load tools to/from the Hub, and more is to come!
\
So yes, first hubs with the tools are already here for us to use. But in the simplest form you already can distribute your tool in the form of the pip packages, since again, it is just a classical software no more no less.
\
Let me give you another, more complex, example of tools that are designed to do real world investments (trade with stocks/options/etc):
\
- Tools to do operations with stocks
- Tools to do operations with options
- You can check more tools in the folder calls
\
Small note: In modern days people often talk about LLM OS. In the concept of LLM OS one should think about tools as drivers, and that is how they would be called in LLM OS drivers that you install in order for LLM OS to be able to execute different actions. Each driver will have its own requirements on the LLM and will be adding new features to the LLM OS upon the installation of it.
Definition – Agents
Agent – is a combination of: tools/ prompt / other agents; that allows one to do one atomic task end to end with predictable level of stability.
\
Let’s start right with the example of a BigQuery agent that is using tools from the example above. Here is a prompt of the agent: \n
You are a helpful assistant that helps to query data from a BigQuery database.
\
You have access to the tools required for this.
\
When using the tool to query:
- SQL Syntax: You MUST generate valid BigQuery SQL.
- String Literals: String literals in SQL queries MUST be enclosed in single quotes (‘). Do NOT use backslashes (\) to escape characters within SQL string literals unless specifically needed for a special character inside the string (e.g., a single quote within the string itself should be escaped as ”).
- Table and Column Names: If table or column names contain special characters or are reserved keywords, enclose them in backticks (`).
- Example
- To query for a runid of “abc-123”, the SQL should be: `SELECT * FROM mytable WHERE run_id = ‘abc-123’`
- Do not use double backslashes: `SELECT * FROM mytable WHERE runid = \\’abc-123\\’`
- Do not use excessive backslashes. Only use them when necessary to escape special characters within a string literal according to BigQuery SQL rules.
- BEFORE doing any query make sure that you have checked table name by calling gettableref and schema from get_schema to make sure that you have constructed the correct SQL
- UNLESS user is asking about SQL query to show, your main goal is to answer the question and not to show the SQL query, do not respond with the query you want to execute – try to get to the answer (unless you got the error and do not know how to proceed)
When generating SQL queries, be concise and avoid unnecessary clauses or joins unless explicitly requested by the user.
Always return results in a clear and human-readable format. If the result is a table, format it nicely.
Arguably one can argue that some parts of the prompt can go to the tools documentation. Which is true. However there are some parts of the prompt that can NOT. For example, there are requirements on how data should be presented back to the user. There are actions that LLM needs to take before calling some tools, etc.
\
Now, imagine that you are building a specialized BigQuery agent on top of the generic one (and to be fair this is the main idea of generic one to be generic – so you can build on top). Let’s say you are building a TODO agent for yourself (most common example that people are doing for educational purposes when they are trying to create their first BigQuery agent on top of our generic BigQuery agent) with the BigQuery table that stores TODOs. Agent has full edit access, it is a single user Agent.
\
\In this example Agent prompt is the only place where you can add information that agent is the TODO agent and its goal is to manage users TODOs (and whatever else you want to put in the prompt). It can not go to tools (since tools are provided to you) it has to go to the agent prompt and thus – agent has to have a prompt.
\
\Finally, since an agent is an entity that can do one task end to end it defines permissions. It does not make any sense to set permissions on the tools level since on the tools level you do not know who will be used and in which way. On the agent level, however, you know exactly which tools are used (and for which tools you need to set permissions). Here is an example of the API call that creates a BigQuery agent that requires passing the BigQuery credentials for its work.
\
\Let’s take another example (agent that allows one to trade on the financial markets). Here is the prompt of that agent:
\
You are a tool for carrying out transactions on the stock market. You act as an interface to interact with the Alpaca markets API.
Key instructions:
- do not be verbose, your task is to provide information, not to explain it, do not comment on what you are doing;
- provide financial advice only at the direct request of the user, because a financial consultant is your second role;
- perform requests clearly and without interpretations based on previous requests;
- communicate professionally, no childish tenderness.
\
Rules for performing functions for interaction with Alpaca:
- always directly perform the function that corresponds to the user’s request;
- if you are not sure which function to use, ask the user for clarification and provide a short list of possible functions;
- if a function returns an error, display it to the user exactly as it is, without changes and own comments;
- it is forbidden to imitate the execution of a function or forge the result of its execution.
\
Rules for working with data:
- always use the latest data from Alpaca;
- I forbid mixing fresh data with previous data on similar requests;
- I forbid drawing conclusions and interpretations based on other data not related to the current request;
- show the user only the data he requested, and other data (those received from Alpaca) in the same request – do not show, ignore;
- if the user asks for full, raw, or unprocessed information for his query, then just give him exactly what the corresponding function for interacting with the Alpaca API returns;
- all the data you provide to the user must be human-readable.
\
As you can see there are many examples from here that does not belong to the documentation of any specific tool call (or will have to be replicated in ALL of them)
Definition – Pipelines
One of the key parts of how we have defined the Agent – “… to do one atomic task end to end …”. How to define “one atomic task” I will leave up to you, since this is a very similar question of how to define one task when you write a new class in python or Java. I believe the majority of the developers have a good intuition of how to do it (and if you do not I probably will not be able to fix it in the scope of several sentences).
\
So what to do if you need to do a more complex sequence of events? Finally we can close the loop on our example of the investor bot. Real world example, we had a customer who needed to instantiate very simple trading strategy, that can expressed in the following way:
\
- Check if there is existing TQQQ limit buy order
- if yes, check if the price is not lower than the current price on the market – 5%
- If yes – cancel and create new buy limit order with price equal to current market price – 5%
- If no – do nothing
- If no, check if there are already shares owned (of TQQQ) in a specified quantity,
- If no, place the limit buy order with the price of the current price – 5%
- If yes, check if there is a limit sell order
- If yes – do nothing
- If no –
- Check the price at which they were bought
- Set the limit sell price of that price +5%
\
Simple strategy, right? But due to the fact that it is actually multi steps, you will be surprised how much of a problem this pipeline creates if you try to execute it in full with one message to the investing agent (even if you are using the most advanced model available). In short, in production it will not produce production required stability/reliability quality even if the most expansive model is used. Furthermore, making it more reliable requires unreasonable investments (like using the most advanced model) when it is actually not necessary.
\
To solve this problem we need to introduce a pipeline. LLM Pipeline is a classical DAG where each step is:
- Utilizing an agent that to deliver one atomic action
- Has well defined structure of the output data it produces (boolean/int/json/etc)
- Has well defined inputs that it requires to execute the task
\
Several specific aspects of the pipeline that are not required but I would not consider using any pipeline framework that does not allow this:
- Steps are agents agnostic (you can use any agent with any step)
- History can be controlled (you can specify which history is passed from which step to which step)
\
With this definition here is an example of the pipeline that we defined earlier:
\
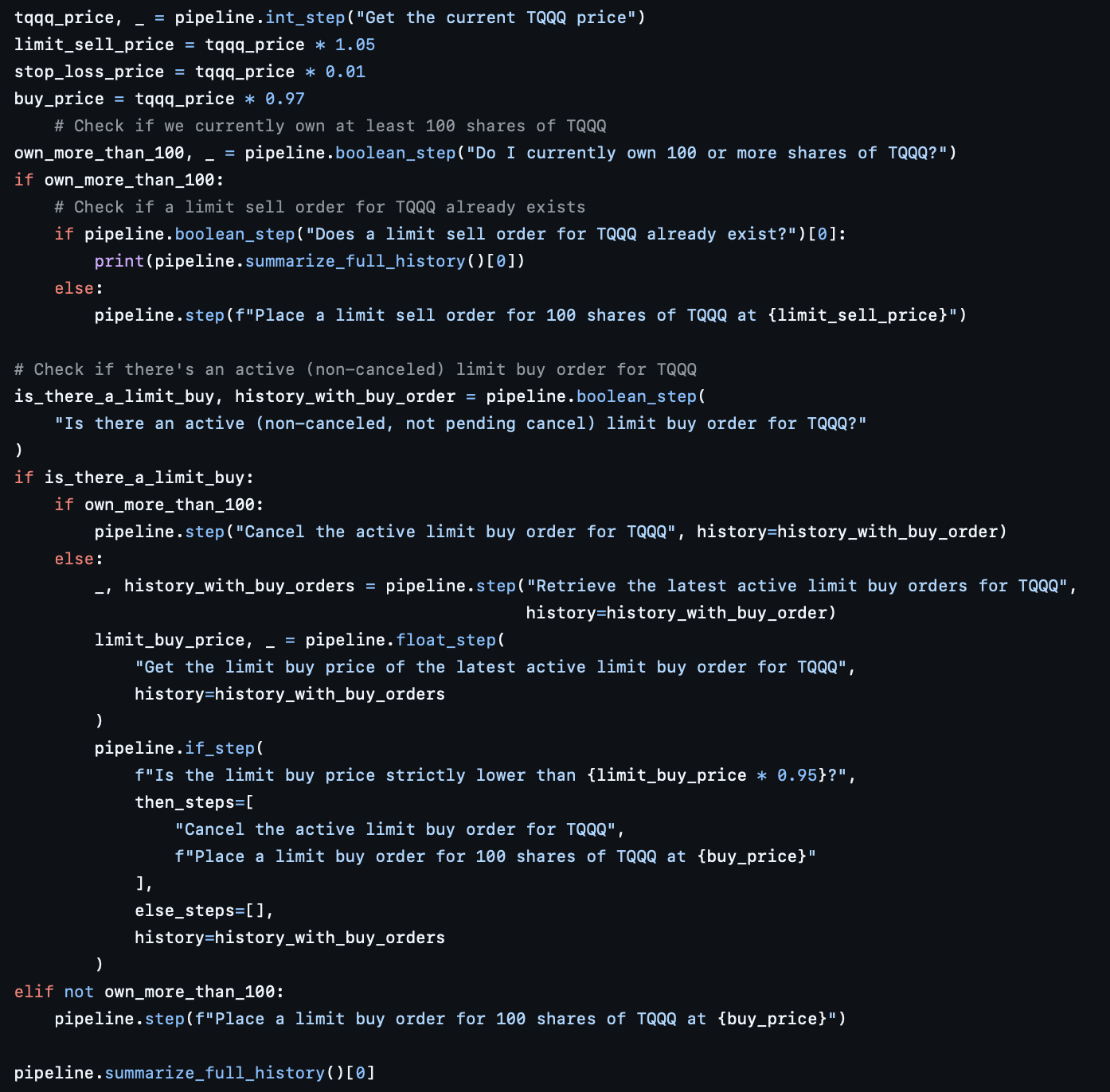
\
As you can see with the example each step is atomic, self sufficient. It has a predictable final type (boolean/float/etc). As a result, in our experiments, the same task on the same agent on the same model went from <50% success rate (of full pipeline execution end to end) when done via one mega prompt to 99+% success rate when executed in the shape of a proper pipeline.
")


