


")


How to Scrape Walmart How to Scrape Walmart Product Page Details with Python?

Why Scrape Walmart?
Walmart is one of the largest e-commerce platforms in the United States, with thousands of products in different categories. Enterprises can scrape Walmart’s data to understand market trends and track price changes. It is a valuable source of data for various industries and use cases.
Walmart also provides user ratings and detailed reviews for each item, which can be challenging to read and analyze manually. By scraping Walmart reviews, we can drive AI learning to study user opinions and experiences with products and sellers.
What Can Walmart Product Scraper do?
The Walmart product details scraper in this article allows you to quickly collect product data from Walmart.com.
Walmart product details scraper can scrape:
- Price
- Description
- Rating
- Other important details from the search listing page
Well, let’s dive into how to build your Walmart product scraper to easily achieve data acquisition!
Method 1: Build Your First Python Walmart Scraper
Step 1: Prerequisites
Before we dive into the magical world of web scraping, let’s make sure we’ve got our tools ready!
Execute the following command to ensure you have a Python environment set up. If not installed, please install Python first.
python --version
We’ll need a few cool libraries to make this work. Install them with this spell—uh, I mean, command:
pip3 install beautifulsoup4 playwright csv
After installation, create a Python file (scraper.py) in your Python IDE and prepare to start coding.
Step 2: Scraping Walmart Product Detail Page Data
For this example, we will use a Walmart product detail page as our target website.
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
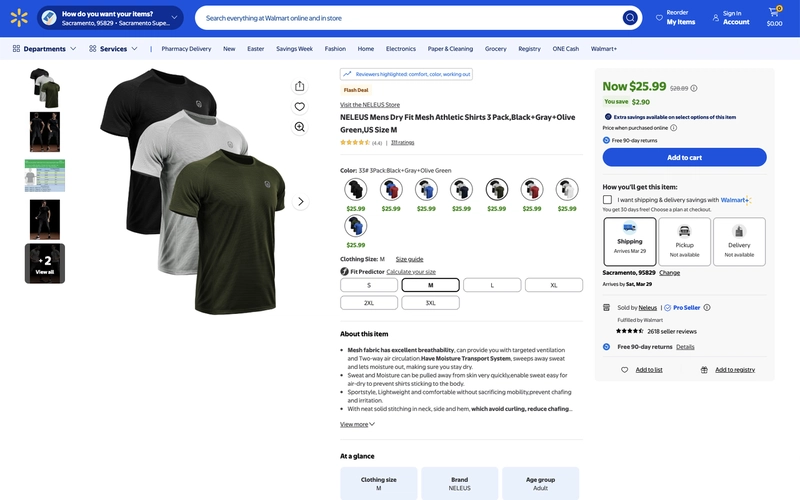
We will analyze its HTML structure and extract the following data:
- Product title
- Product description
- Product price
- Product images
Fetching Product HTML Data
First, write the following code in the previously created scraper.py file:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import csv
# define target website url
url = "https://www.walmart.com/ip/NELEUS-Mens-Dry-Fit-Mesh-Athletic-Shirts-3-Pack-Black-Gray-Olive-Green-US-Size-M/439625664?classType=VARIANT"
# use playwright to scrape the website
with sync_playwright() as p:
# launch the browser
browser = p.chromium.launch(headless=False)
# create a new page
page = browser.new_page()
# navigate to the target website
page.goto(url)
# wait for the page to load
page.wait_for_load_state("load")
# get the page content
html = page.content()
# close the browser
browser.close()
soup = BeautifulSoup(html, "html.parser")
print("successfully scraped the website", soup.title.text)
In the code above, we used Playwright to fetch the website’s HTML content and BeautifulSoup to parse it. We first defined the target URL, then used Playwright to open a browser, visit the page, wait for it to load, retrieve the content, and finally close the browser. We then parsed the HTML with BeautifulSoup and printed the page title.
You should see output similar to this:
![]()
However, since Walmart has anti-scraping measures, you might encounter the following message:

This indicates that our script was detected as a bot. To avoid this, we need to add code to simulate human behavior. Don’t worry—later, we’ll discuss better methods to prevent such issues.
Extracting the Product Name
In the previous step, we successfully retrieved the HTML content. Now, we’ll extract the product name.
To extract the product name from the HTML, we first need to locate the HTML element containing it. Using the browser’s developer tools (press F12), click the arrow icon in the top-left corner of the tools, then click the product name on the page. The corresponding HTML element will be highlighted.
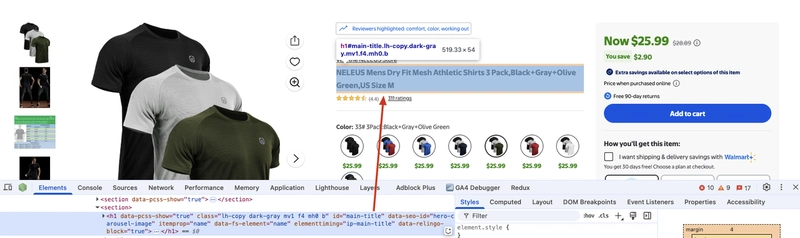
We can see that the product name is inside an tag with the ID main-title. Using BeautifulSoup, we can extract its text. Let’s modify scraper.py to fetch the product name:
...
soup = BeautifulSoup(html, "html.parser")
product_name = soup.find("h1", id="main-title").text
print("Product Name:", product_name)
You should see output like this, confirming we’ve successfully retrieved the product name:

Extracting the Product Description
After the above operation, we continue to search for product description information. We can see that the product description information is located in the span tag, and the id attribute value of the span tag is product-description-atf, so we can use BeautifulSoup to extract the content of the tag.
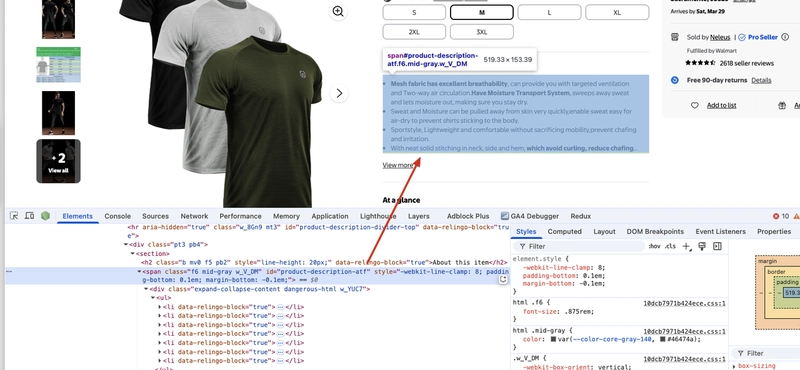
Note that the product description information is located in the li tag under the span, and there are multiple li tags. We need to traverse all li tags to extract the product description information.
Let’s modify the scraper.py file to extract the product description information.
...
description_data = []
description_container = soup.find(id="product-description-atf")
description_lists = description_container.find_all("li")
for list in description_lists:
description_data.append(list.text.strip())
print(description_data)
We traverse to find all li tags and save their contents in description_data. In the end, we will see the following output

Extract product prices
Next, we extract product price information. We can see that the product price information is in the span tag, and the itemprop attribute value of the span tag is price, so we can use BeautifulSoup to extract the content of the tag.
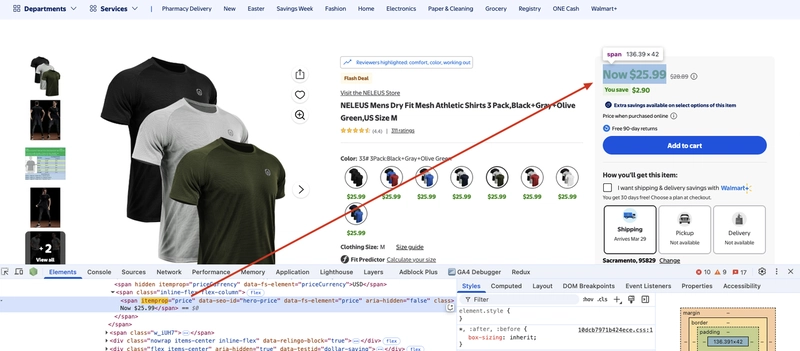
Let’s modify the scraper.py file to extract the product price information.
...
price = soup.find("span", {"itemprop": "price"}).text.strip()
print(price)
You will see the following output:

Extract product images
Finally, we extract the product image information. We can see that the product image information is in the div tag, and the data-testid attribute value of the div tag is vertical-carousel-container, so we can use BeautifulSoup to extract the content of the tag.
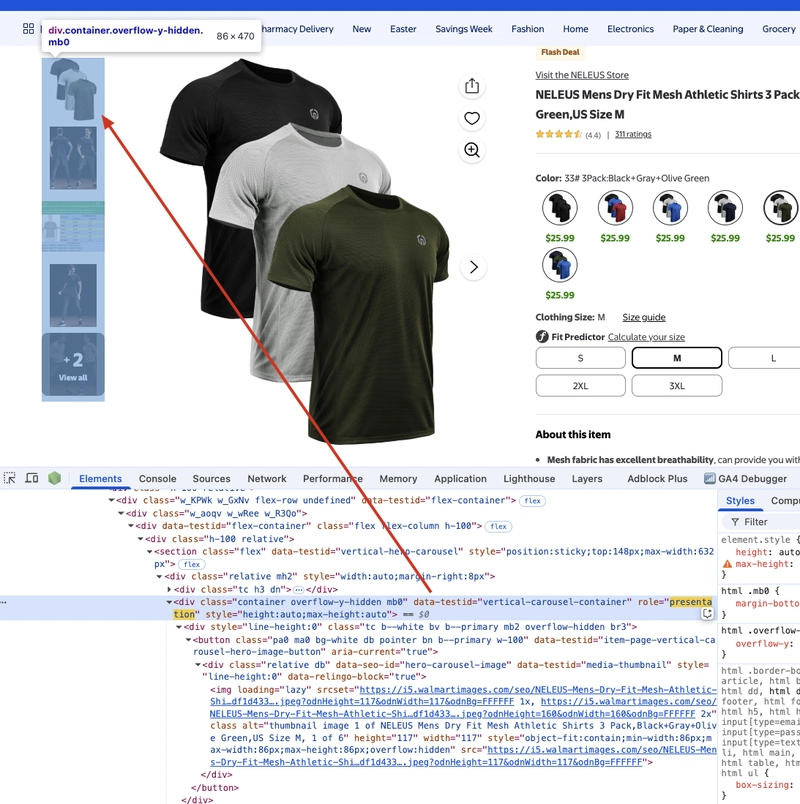
Note: Here the product description information is in the img tag under div, and there are multiple img tags. We need to traverse all img tags to extract the product image information. So we can use BeautifulSoup’s get method to extract the src content of the tag.
Let’s modify the scraper.py file to extract the product image information.
...
image_data = []
carousel_container = soup.find("div", {"data-testid": "vertical-carousel-container"})
images = carousel_container.find_all("img")
for image in images:
image_data.append(image.get("src"))
print(image_data)
We will see the following output:

Step 3: Export data
First, we integrate the previous step code and output the completed code example as follows:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import csv
# define target website url
url = "https://www.walmart.com/ip/Logitech-MX-Master-3S-Wireless-Performance-Mouse-Ergo-8K-DPI-Quiet-Clicks-USB-C-Black/731473988"
# use playwright to scrape the website
with sync_playwright() as p:
# launch the browser
browser = p.chromium.launch(headless=False)
# create a new page
page = browser.new_page()
# navigate to the target website
page.goto(url)
# wait for the page to load
page.wait_for_load_state("load")
# get the page content
html = page.content()
# close the browser
browser.close()
soup = BeautifulSoup(html, "html.parser")
product_data = []
# find and get product name
product_name = soup.find(id="main-title").text.strip()
# find and get product price
price = soup.find("span", {"itemprop": "price"}).text.strip()
# find and get product images
image_data = []
carousel_container = soup.find("div", {"data-testid": "vertical-carousel-container"})
images = carousel_container.find_all("img")
for image in images:
image_data.append(image.get("src"))
# find and get product description
description_data = []
description_container = soup.find(id="product-description-atf")
description_lists = description_container.find_all("li")
for list in description_lists:
description_data.append(list.text.strip())
# append the scraped data to the product_data list
product_data.append({
"Product Name": product_name,
"Price": price,
"Images": image_data,
"Product Description": description_data,
})
# export the data to a CSV file
with open("walmart.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=product_data[0].keys())
writer.writeheader()
for data in product_data:
writer.writerow(data)
print("successfully exported to CSV")
In the above code, we use BeautifulSoup to extract the product name, description, price and image information. We can save all of them into a CSV file.

Scraping API: Get Walmart Data Easily
Why use an API to retrieve Walmart product details?
1. Improved Efficiency
Manual search for product data is slow and error-prone. API allows automatic retrieval of Walmart product information, ensuring fast and consistent data collection.
2. Accurate, real-time data
The Scrapeless API extracts data directly from Walmart product pages, ensuring that the retrieved information is up-to-date and accurate. This prevents errors caused by delayed manual entry or outdated sources.
3. Applicable to various business scenarios
- Price monitoring: Compare competitor prices and adjust pricing strategies.
- Inventory tracking: Check product availability to optimize supply chain management.
- Review analysis: Analyze customer feedback to improve products and services.
- Market research: Identify popular products and make informed business decisions.
How much will a Walmart product API cost?
Scrapeless offers a $2 free trial for every user. You can get 1,300 products from Walmart Product Detail Scraper, so these results will be completely free!
If you have a lot of scraping needs and want to get more additional tools: Scraping Browser, Proxies, Universal Scraping API, please consider subscribing to Scrapeless. We recommend the $49/month starter plan. Not only will you use all of Scrapeless’ services, but you will also get a 10% discount (the higher the subscription plan, the bigger the discount).
Join the community now to get a free trial.
Using steps
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
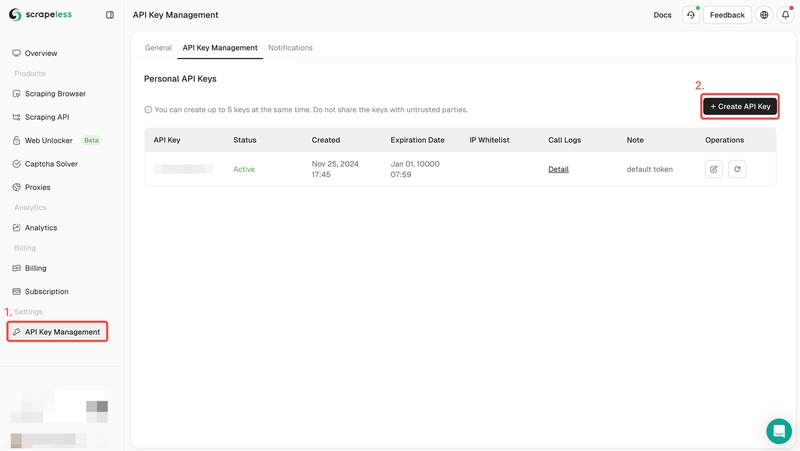
Step 1. Create your API Token
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, simply click on the API Key to copy it.
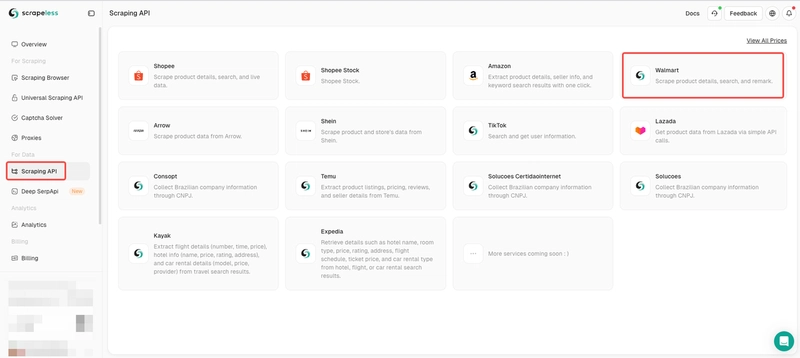
Step 2. Enter Walmart product API
- Click Scraping API under For Data
- Find TikTok and enter
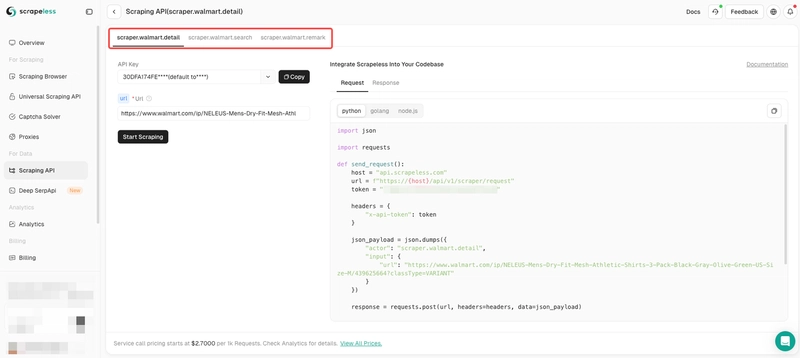
Step 3. Request parameter configuration
The Walmart actor currently has three scraping scenarios:
-
Walmart product details: Extract product details info via target URL.
-
Keywords’ search results: Extract search results by inputing keywords.
-
Remark scraper: Extract the comments of a product.
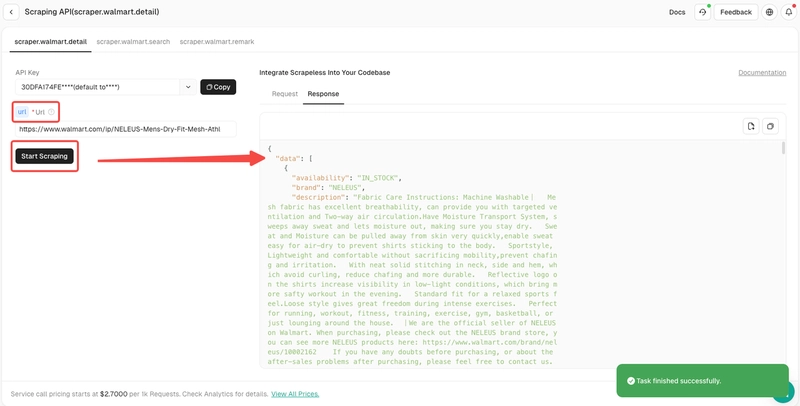
Are you ready? After understanding the basic information, we can officially start scraping data! Now you only need to copy the product URL and paste on the url parameter.
After confirming that everything is correct, just click Star Scraping to easily get the scraping results.
The Ending Thoughts
Scraping Walmart product information can provide practical reference for businesses and individuals who want to conduct competitive market analysis. However, Walmart’s anti-bot defense system may block your request and deny your access.
How to scrape Walmart product data in the fastest and easiest way?
A Warlmat product API will help you escape from a trap!



