





PWC 312 Time to be random

Weekly Challenge 312 is here. 312 is the telephone area code in and around Chicago. Once upon a time, when I dressed so fine, threw the bums a dime in my prime, it was my area code, but then we ran out of phone numbers and, like a soccer team falling on hard times, the suburbs were relegated to the far less prestigious 708 (12×59 — what kind of useless factoring is that?), and then the only slightly better 630 (2×3×5×7 × 3).
Be that as it may, here we are, ticking away the moments that make up a dull day, and so we are going to fritter and waste the hours in an off-hand way solving a couple of programming problems.
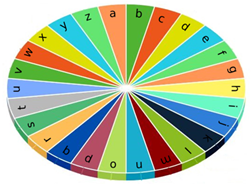
You are given a typewriter with lowercase
English letters a to z arranged in a circle.
Typing a character takes 1 sec. You can
move the pointer one character at a time
clockwise or counter-clockwise. The pointer
initially points at 'a'.
Write a script to return the minimum time it
takes to print the given string.
-
Example 1: Input:
$str = "abc"Output:5- The pointer is at ‘a’ initially.
- 1 sec – type the letter ‘a’
- 1 sec – move pointer clockwise to ‘b’
- 1 sec – type the letter ‘b’
- 1 sec – move pointer clockwise to ‘c’
- 1 sec – type the letter ‘c’
-
Example 2: Input:
$str = "bza"Output:7- The pointer is at ‘a’ initially.
- 1 sec – move pointer clockwise to ‘b’
- 1 sec – type the letter ‘b’
- 2 sec – move pointer counter-clockwise to ‘z’
- 1 sec – type the letter ‘z’
- 1 sec – move pointer clockwise to ‘a’
- 1 sec – type the letter ‘a’
-
Example 3: Input:
$str = "zjpc"Output:34
The plan
Each time we type a letter, that takes one second, so the time will be at least the length of the string.
To that, we need to add the time to move from one letter to the next, starting with the finger poised over ‘a’. Going around the circle is modulo arithmetic, but we need to check both directions and pick the shorter.
The code
sub minTime($str)
{
# List of pointer positions, beginning at A
my @ptr = (0, map { ord($_) - ord("a") } split(//, $str));
# Array of closest differences between positions
my @d = slide { min(($a - $b) % 26, ($b-$a) % 26 ) } @ptr;
# One second for each character in str, plus time to move
my $t = length($str) + sum0(@d);
return $t;
}
Notes:
-
split(//, $str)Turn the string into a list of characters -
map ord($_) - ord("a") }Turn the characters into indices between 0 and 25 -
my @ptr = (0, ...)The hovering finger is initially over ‘a’, so insert a 0 into the front of the positions.-
slide { ... }FromList::MoreUtils, move across the list a pair at a time. Make a list of differences between character positions.
-
No loops, no index variables, no off-by-one errors.
There are $n balls of mixed colors: red, blue or
green. They are all distributed in 10 boxes labeled 0-9.
You are given a string describing the location of balls.
Write a script to find the number of boxes containing
all three colors. Return 0 if none found.
-
Example 1 Input:
$str = "G0B1R2R0B0"-
Output:
1 - The given string describes there are 5 balls as below:
- Box 0: Green(G0), Red(R0), Blue(B0) => 3 balls
- Box 1: Blue(B1) => 1 ball
- Box 2: Red(R2) => 1 ball
-
Output:
-
Example 2 Input:
$str = "G1R3R6B3G6B1B6R1G3"-
Output:
3 - The given string describes there are 9 balls as below:
- Box 1: Red(R1), Blue(B1), Green(G1) => 3 balls
- Box 3: Red(R3), Blue(B3), Green(G3) => 3 balls
- Box 6: Red(R6), Blue(B6), Green(G6) => 3 balls
-
Output:
-
Example 3 Input:
$str = "B3B2G1B3"-
Output:
0 - Box 1: Green(G1) => 1 ball
- Box 2: Blue(B2) => 1 ball
- Box 3: Blue(B3) => 2 balls
-
Output:
The plan
We’ll need to split up the input string and create a representation of balls in boxes. Two ways come to me quickly
- an array of 10 strings, one for each box. The G, B, or R from the input is appended onto its box.
- an array of 10 lookup tables. Each box has a little hash that counts the number of G, B, or R balls from the input.
Once the balls are categorized by box, then we can check how many boxes contain at least one of G, B, and R. In a string, that can be a regular expression match, or a simple index function. In the hash, it would be a search for counts greater than zero.
The code, with regular expressions
sub ballBox($str)
{
my @box = ("") x 10;
for my ($color, $b) (split(//, $str)) # As of 5.36, multiple values allowed
{
$box[$b] .= $color;
}
return scalar grep { /B/ && /G/ && /R/ } @box;
}
Notes:
-
my @box = ("") x 10An array of 10 boxes (0 to 9), each initialized with an empty string. -
for my ($color, $b) ...My favorite recent perl addition: processing tuples out of an array. -
$box[$b] .= $colorDistribute balls into their boxes. -
grep { /B/ && /G/ && /R/ }Easiest way to use regular expressions to mean all three must be present. -
return scalar ...I only want a zero/non-zero return code. If the function is used in an array context (which it is in a unit testis()statement), it returns a list instead of a number. No want.
The code, without regular expressions
sub ballBox_idx($str)
{
my @box = ("") x 10;
for my ($color, $b) (split(//, $str)) # As of 5.36, multiple values allowed
{
$box[$b] .= $color;
}
return scalar grep { index($_, "G") >= 0 && index($_, "B") >= 0 && index($_, "R") >= 0 } @box;
}
This is almost the same, except that the regular expression matches have been replaced by index() checks. Even though regular expressions are efficient, there’s a lot going on under the hood, and I suspect (but need to check) that a simple string scan might be faster.
The code, with a hash
sub ballBox_hash($str)
{
my @box;
for my ($color, $b) (split(//, $str))
{
$box[$b]{$color}++;
}
return scalar grep { $_->{G} && $_->{B} && $_->{R} } @box;
}
Once again, we split the string in a similar way, but this time we’re going to count occurrences.
The performance
My intuition for performance is notoriously bad. Let’s set up a benchmark test. I’ll create a random string that distributes balls randomly, and run 50,000 or so iterations of each variation.
sub runBenchmark($repeat)
{
use Benchmark qw/cmpthese/;
my $str;
foreach my $color ( qw(R G B ) )
{
$str .= $color . int(rand(10)) for 1 .. 25;
}
cmpthese($repeat, {
grep => sub { ballBox($str) },
index => sub { ballBox_idx($str) },
hash => sub { ballBox_hash($str) },
});
}
bash-3.2$ perl ch-2.pl -b 50000
Rate hash grep index
hash 44248/s -- -3% -12%
grep 45455/s 3% -- -9%
index 50000/s 13% 10% --
This time, I’m at least partially right. Using simple string functions slightly beats hash tables and regular expressions, at least for randomly distributed data of a moderate number of balls.
I should also check for other distributions that are most likely in my actual application, like mostly empty boxes, or very large numbers of balls, or combinations like thousands of green balls but only a few red.
However, I’m going to randomly reclaim my time and call it a win.



