




Streaming de datos Serverless con Aurora DSQL

La gestión y procesamiento de datos en tiempo real es una necesidad creciente en la actualidad. En este artículo, exploraremos cómo construir una solución serverless para procesar archivos CSV y cargarlos automáticamente en Aurora DSQL utilizando servicios de AWS.
Introducción
El streaming de datos permite procesar información en tiempo real, tan pronto como se genera. En este caso, implementaremos un sistema que detecta cuando se carga un archivo CSV en un bucket de S3 y automáticamente procesa y carga los datos en una base de datos Aurora DSQL.
Esta solución combina varios servicios de AWS:
Amazon S3 para almacenamiento de archivos.
AWS Lambda para procesamiento serverless.
Amazon EventBridge para eventos y comunicación entre servicios.
Amazon Aurora DSQL para el almacenamiento de datos.
AWS SAM para la implementación de infraestructura como código
Arquitectura de la solución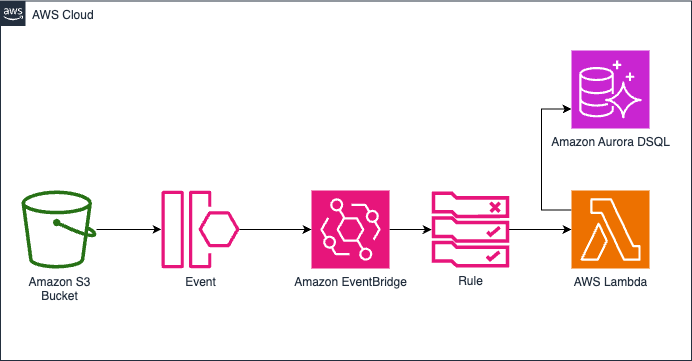
La arquitectura se compone de:
- Un bucket S3 donde se cargan los archivos CSV.
- EventBridge que detecta la carga de nuevos archivos.
- Una función Lambda que procesa los archivos y valida los datos.
- Aurora DSQL donde se almacenan los datos procesados.
Implementación con AWS SAM
AWS SAM (Serverless Application Model) nos permite definir toda nuestra infraestructura como código. Veamos cómo se estructura nuestro template:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
streaming-dsql
Sistema serverless para streaming de datos a Aurora DSQL
Globals:
Function:
Timeout: 5
MemorySize: 128
Runtime: python3.12
Layers:
- !Sub arn:aws:lambda:${AWS::Region}:017000801446:layer:AWSLambdaPowertoolsPythonV3-python312-x86_64:7
Parameters:
ClusterId:
Description: Aurora DSQL Cluster Id
Type: String
BucketName:
Type: String
Description: Nombre del bucket de S3
Resources:
StreamingFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: lambdas/streaming_dsql/
Handler: app.lambda_handler
Architectures:
- x86_64
Policies:
- Version: '2012-10-17'
Statement:
- Sid: DsqlDataAccess
Effect: Allow
Action:
- dsql:DbConnectAdmin
Resource:
- !Sub arn:aws:dsql:${AWS::Region}:${AWS::AccountId}:cluster/${ClusterId}
- Sid: S3GetObject
Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub arn:aws:s3:::${BucketName}/*
Events:
S3EventBridgeRule:
Type: EventBridgeRule
Properties:
Pattern:
source:
- aws.s3
detail-type:
- "Object Created"
detail:
bucket:
name:
- !Ref BucketName
Environment:
Variables:
POWERTOOLS_SERVICE_NAME: StreamingDsql
POWERTOOLS_METRICS_NAMESPACE: Powertools
LOG_LEVEL: INFO
REGION: !Ref AWS::Region
DSQL_CLUSTER_ENDPOINT: !Sub "${ClusterId}.dsql.${AWS::Region}.on.aws"
DATA_BUCKET: !Ref BucketName
Bucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Ref BucketName
NotificationConfiguration:
EventBridgeConfiguration:
EventBridgeEnabled: true
Este template define la función Lambda con permisos para acceder a S3 y Aurora DSQL, así como el bucket S3 con notificaciones EventBridge habilitadas.
Procesamiento de datos con AWS Lambda y Powertools
Para la implementación de la función Lambda utilizamos AWS Lambda Powertools, una biblioteca que facilita la implementación de buenas prácticas como la validación de datos, métricas y trazas.
 El repo completo encuentran en GitHub
El repo completo encuentran en GitHub
Validación de datos con JSON Schema
Una parte crucial del proceso es la validación de datos. Para esto, utilizamos JSON Schema a través de las utilidades de validación de AWS Lambda Powertools.
 Powertools for AWS Lambda: Validation
Powertools for AWS Lambda: Validation
Esta validación garantiza que los datos cumplan con nuestros requisitos antes de insertarlos en la base de datos.
Despliegue de la solución
Para desplegar nuestra solución, utilizamos los comandos de AWS SAM:
# Empaquetar la aplicación
sam build
# Desplegar la aplicación
sam deploy --guided
Para instalar AWS SAM CLI, sigue los pasos en la guía oficial de instalación.
Durante el despliegue guiado, se nos pedirá que proporcionemos los valores para nuestros parámetros, como el ID del clúster de Aurora DSQL y el nombre del bucket de S3.
Ventajas de esta arquitectura
Esta solución serverless ofrece varias ventajas:
Escalabilidad automática: AWS Lambda escala automáticamente según la carga de trabajo.
Sin servidores que administrar: No hay infraestructura que gestionar.
Procesamiento en tiempo real: Los datos se procesan tan pronto como se cargan.
Alta disponibilidad: Los servicios de AWS son altamente disponibles.
Costo-eficiente: Solo pagas por lo que usas.
Validación robusta: La validación de datos garantiza la calidad de la información.
Consideraciones de seguridad
- Se utilizan permisos de IAM restringidos para la función Lambda.
- La conexión a Aurora DSQL se realiza mediante tokens temporales.
- La comunicación con Aurora DSQL se realiza mediante SSL.
- Los datos se validan antes de ser insertados en la base de datos.
Conclusión
La combinación de servicios Serverless de AWS nos permite construir soluciones robustas para el streaming de datos. Con AWS SAM, podemos definir toda nuestra infraestructura como código, lo que facilita la implementación y el mantenimiento.
Aurora DSQL nos proporciona una base de datos compatible con PostgreSQL con la ventaja de ser Serverless, lo que nos permite escalar según nuestras necesidades sin tener que preocuparnos por la infraestructura desplegada.
Con esta arquitectura, podemos procesar grandes volúmenes de datos en tiempo real, validarlos y almacenarlos de manera eficiente, todo con un mínimo esfuerzo de administración.


?")
