





Tidy & Wrap Up – Project Stage 03

Introduction
Welcome to the final blog post of SPO600 series! 
This stage of the project will focus on enhancing some features as well as fix anything from stage 02.
You might remember from stage 02, the code was running on x86, but failing on AArch64 with a segmentation fault. This would be my first thing to fix before I could proceed with implementing the new functionality.
Debugging the AArch64 Segmentation Issue
Looking at the error backtrace from AArch64, I can see that my GCC pass is crashing in the compare_functions method when trying to print GIMPLE statements.
The issue is in how I’m calling print_gimple_stmt. On AArch64, the statement might have unexpected structures or null pointers that cause the printing function to crash. This part:
if (gimple_code(stmt1) != gimple_code(stmt2)) {
if (dump_file) {
fprintf(dump_file, "Statement %zu: Different gimple codes\n", i);
print_gimple_stmt(dump_file, stmt1, 0, TDF_SLIM); // Line 164 - causing crash
print_gimple_stmt(dump_file, stmt2, 0, TDF_SLIM);
}
return false;
}
Add a safety check and I’ll modify the function to print in another way as it is the one that is causing the issue.
// Iterate through statements and compare them
for (size_t i = 0; i < func1_stmts.size(); i++) {
gimple *stmt1 = func1_stmts[i];
gimple *stmt2 = func2_stmts[i];
// Add safety check for null statements
if (!stmt1 || !stmt2) {
if (dump_file) {
fprintf(dump_file, "Statement %zu: One or both statements are null\n", i);
}
return false;
}
// Check if statement codes are different
if (gimple_code(stmt1) != gimple_code(stmt2)) {
if (dump_file) {
fprintf(dump_file, "Statement %zu: Different gimple codes (%d vs %d)\n",
i, gimple_code(stmt1), gimple_code(stmt2));
// Use safer printing method without TDF_SLIM flag, which might be causing issues on AArch64
fprintf(dump_file, "Statement 1 code: %d\n", gimple_code(stmt1));
fprintf(dump_file, "Statement 2 code: %d\n", gimple_code(stmt2));
}
return false;
}
// Rest of the comparison logic...
}
// ...
}
Now, let’s run this code in our /spo600/examples/test-clone directory. The details for running this code has been presented in the previous stage 02.
This is the output after running make all.
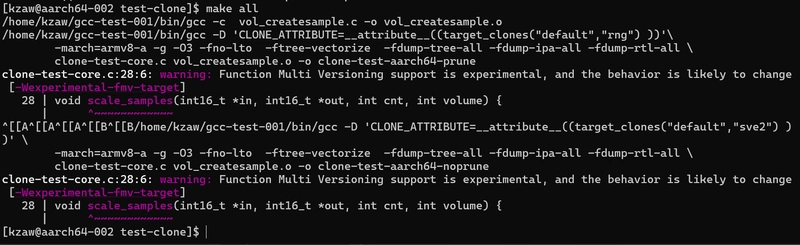
There seems to be no more segmentation fault and the program seemed to have been compiled by GCC. Let’s check our dump file.

This seems to be working, so that’s done!
Guaranteeing Prune Output for Every Function
During stage 2, I discovered that non‑clone functions (like main, .resolver, or any routine without a . suffix) were being silently skipped. There was no decision at all for these functions.
I want to fix it so that there is a prune decision for every single function, regardless of here is a variant or not.
First, as soon as we enter execute, if we deem it as not a clone by our is_clone_function, print a decision and return immediately.
bool is_clone_or_default = is_clone_function(fndecl, base_name, variant);
if (!is_clone_or_default) {
const char *func_name = IDENTIFIER_POINTER(DECL_NAME(fndecl));
if (dump_file)
fprintf(dump_file, "NOPRUNE: %s\n", func_name);
return 0;
}
if (is_clone_or_default) {
// The rest ...
}
Next, when we push a .default into the group, check if its the only member. If so, there’s nothing to prune against, so print “NOPRUNE: base.default” right away.
Change that part to this:
if (is_clone_or_default) {
// Some code.....
auto &group = clone_groups[base_name];
group.push_back(info);
if (info.variant == ".default" && group.size() == 1) {
if (dump_file)
fprintf(dump_file, "NOPRUNE: %s%s\n",
base_name.c_str(), info.variant.c_str());
return 0;
}
Now, when we check the test code, we can see every function has a decision attached to it!
Default
Variant
Function without variant
Resolver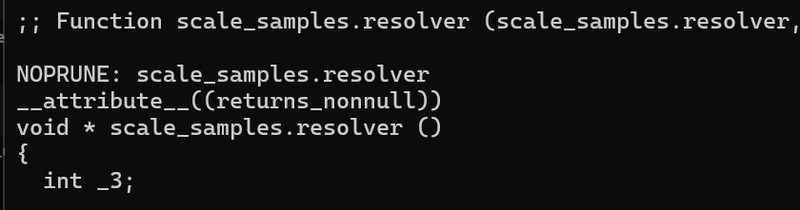
Main
So that is working!
When we run the same thing in AArch64 we can see that it runs as well.
Creating Test Cases
Now, we will need to create test cases to see if it can process multiple sets of cloned functions.
Source code for test cases: Here
The test will have 2 functions.
#include
-
add_numbersis a very simple arithmetic function. The compiler can easily optimize both variants to nearly identical code. So it is a great candidate for PRUNE. -
process_arrayhas more data-dependent branching and loop-based behavior. The clones may diverge more due to architecture-specific vectorization, likely a NOPRUNE. -
You need that CLONE_ATTRIBUTE for what we’re going to do in the
Makefile
Now, that’s not all. We have created the test but we need to modify the Makefile. Essentially we want our Makefile to compile two versions per architecture. (PRUNE and NOTPRUNE).
We also want to inject the target_clones attribute via macro. (This was done in the sample test that we used before).
Add these to the Makefile:
# x86‑64 PRUNE build
clone-test-x86-tc1-prune: test1.c $(LIBRARIES)
$(CC) -D 'CLONE_ATTRIBUTE=__attribute__((target_clones("default","popcnt")))' \
-march=x86-64 $(CFLAGS) test1.c $(LIBRARIES) -o $@
# x86‑64 NOPRUNE build
clone-test-x86-tc1-noprune: test1.c $(LIBRARIES)
$(CC) -D 'CLONE_ATTRIBUTE=__attribute__((target_clones("default","arch=x86-64-v3")))' \
-march=x86-64 $(CFLAGS) test1.c $(LIBRARIES) -o $@
# AArch64 PRUNE build
clone-test-aarch64-tc1-prune: test1.c $(LIBRARIES)
$(CC) -D 'CLONE_ATTRIBUTE=__attribute__((target_clones("default","rng")))' \
-march=armv8-a $(CFLAGS) test1.c $(LIBRARIES) -o $@
# AArch64 NOPRUNE build
clone-test-aarch64-tc1-noprune: test1.c $(LIBRARIES)
$(CC) -D 'CLONE_ATTRIBUTE=__attribute__((target_clones("default","sve2")))' \
-march=armv8-a $(CFLAGS) test1.c $(LIBRARIES) -o $@
This is referenced from the professor’s test case. Basically for each of our function in the test case there will be PRUNE and NOPRUNE builds. The CLONE_ATTRIBUTE helps us with that.
Make sure to add our builds in the BINARIES macro.
AARCH64_BINARIES = clone-test-aarch64-prune clone-test-aarch64-noprune clone-test-aarch64-tc1-prune clone-test-aarch64-tc1-noprune
X86_BINARIES = clone-test-x86-prune clone-test-x86-noprune clone-test-x86-tc1-prune clone-test-x86-tc1-noprune
Now run make all again, and check the dump files.
make all
nano clone-test-x86-tc1-noprune-test1.c.265t.kzaw
nano clone-test-x86-tc1-prune-test1.c.265t.kzaw
Test Case Results
x86 NOPRUNE Build
Default add_numbers:

Default process_array:
process_array.popcnt:
add_numbers.popcnt:
The function dumped ‘NOPRUNE’ for resolvers and main.
x86 PRUNE Build
Default add_numbers:
Default process_array:
process_array.popcnt:
add_numbers.popcnt: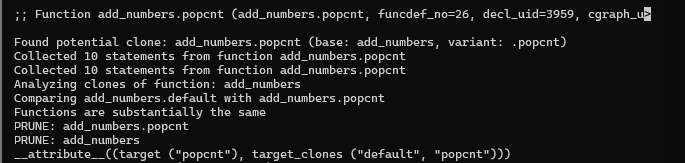
The function dumped ‘NOPRUNE’ for resolvers and main.
You will notice that
add_numbersis PRUNE for both builds. That’s because it is too simple. Any modern architecture (even with vectorization, popcnt, etc.) will generate the same instructions for this function.
AArch64 NOPRUNE Build
Default add_numbers:
Default process_array:
process_array.sve2:
add_numbers.sve2: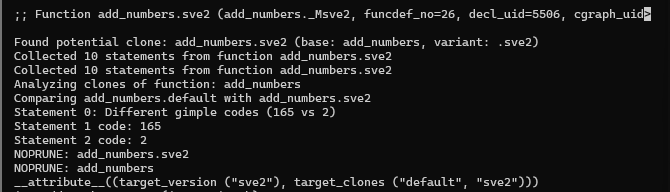
The function dumped ‘NOPRUNE’ for resolvers and main.
AArch64 PRUNE Build
Default add_numbers:
Default process_array:
process_array.rng:
add_numbers.rng:
The function dumped ‘NOPRUNE’ for resolvers and main.
—
Source Code
Please note that all source code is available on my GitHub.
You will find 3 files under /stage03/
-
Makefile: Makefile needed for running tests -
test1.c: Test file -
tree-kzaw-fix-prune.cc: Updated pass
Conclusion
Overall, this specific project stage allowed me to understand more about writing test cases for the pass. We’ve learnt much about compiling and adding logic to pass in the previous stages, and learning about test cases is a full circle moment. I learnt not only about writing a specific test.c logic but also how to write a Makefile to run alongside the tests.
This whole project and SPO600 series enabled me to think deeper and dive into the world of assembly language. From the basic 6502 language to actually working on the gcc compiler, it’s all such a cool experience. I will cherish the learnings I have obtained from this course, and I’m sure understanding the most basic language will help me become a better programmer!
Thank you so much for following me along on this journey. Till next time ~



